SWIFT: NGRAN — Navigating Spectral Utilization, LTE/WiFi Coexistence, and Cost Tradeoffs in Next Gen Radio Access Networks through Cross-Layer Design
Research | | Links:
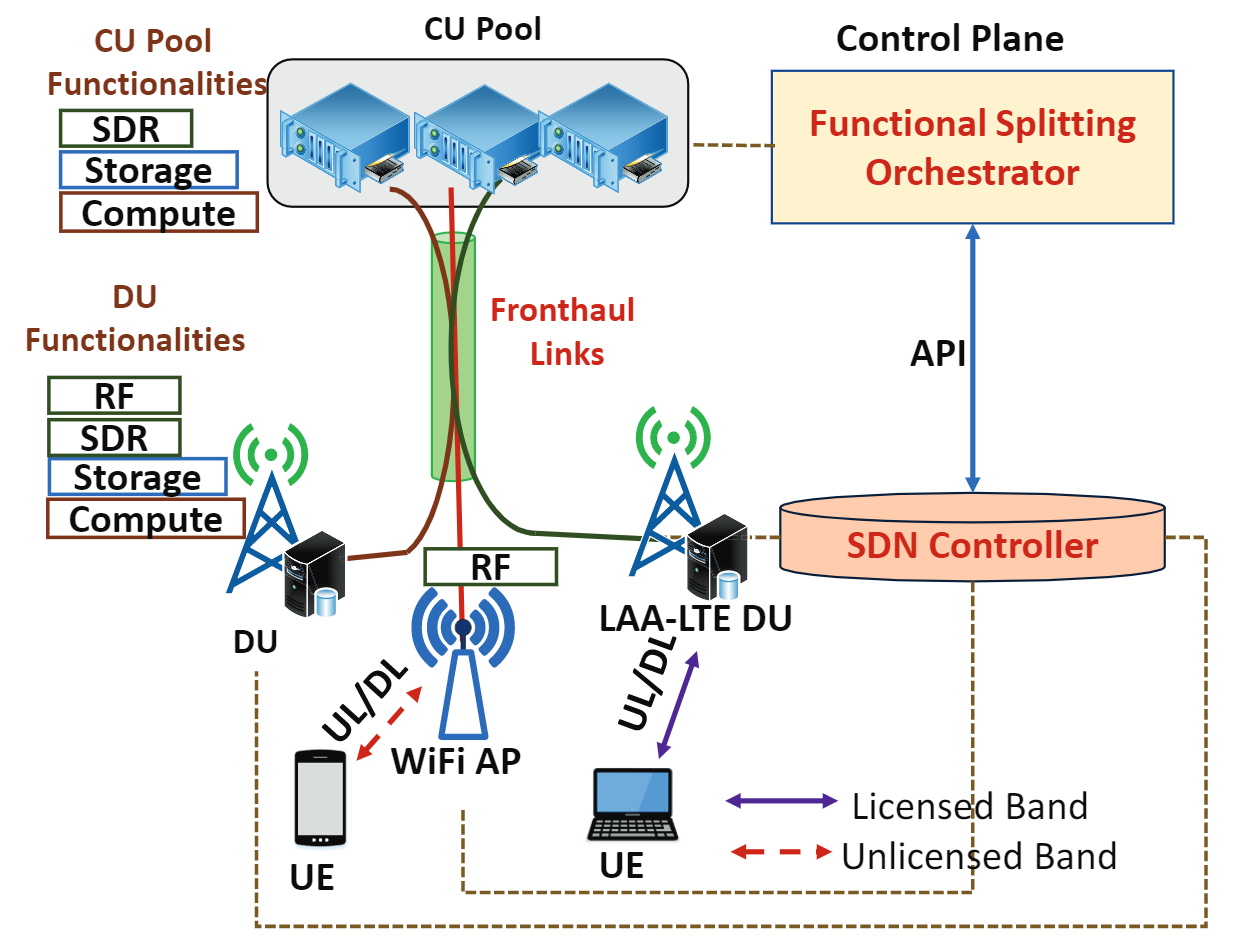
Our goal is to design, develop, and validate experimentally novel communication algorithms and protocol solutions that—within the emerging “communications-in-the-cloud paradigm”—leverage Software Defined Networking (SDN) and Network Function Virtualization (NFV) to trade off between spectral and computing-resource utilization while allowing LTE/WiFi coexistence in Next Generation Radio Access Networks through cross-layer design. To support the heterogeneous requirements of 5G applications, our xl NGRAN architecture provides dynamic designations such as back/mid/front-haul functionalities to physical infrastructure for experimental functional splitting, caching, and computation offloading (Fig. 1)
Our Vision
In Next Generation Radio Access Network (NG-RAN) architecture, most of the communication functionalities are implemented (in part or fully) in a virtualized environment hosted over general-purpose computing servers that are housed in one or more racks in a nearby cloud datacenter. It is therefore crucial to design and provision the virtualized environment properly in order to make it flexible and energy efficient while also capable of handling intensive computations. Such a virtualized environment can be realized via the use of Virtual Machines (VMs). A benefit of virtualizing Central Unit (CU) is that the CU can be dynamically resized ‘on the fly’ in order to meet the fluctuations in capacity demands. This elasticity will enable significant improvement in user Quality of Service (QoS) as well as efficiency in energy and computing resource utilization in NG-RANs. In this research task, we seek to design an efficient bandwidth-aware resource-allocation solution, considering the computational requirements of the virtualized CU over a real-world implementation of NGRAN framework. Software implementations on real hardware are essential to understand the run-time complexity as well as the performance limits of the Baseband Unit (BBU) in terms of processing throughput and latency, and how they translate to mobile-user QoS metrics. The realization of the NG-RAN emulation testbed on virtualized general-purpose servers will allow for profiling of the computational complexity of the communication functionalities implemented in software. In particular, such profiling results will provide a ‘‘mapping’’ from the number and combination of different types of user traffic to VM computational capacity. Hence, we aim at establishing empirical models for the estimation of processing time and CPU utilization w.r.t. different radio-resource configurations and traffic loads.
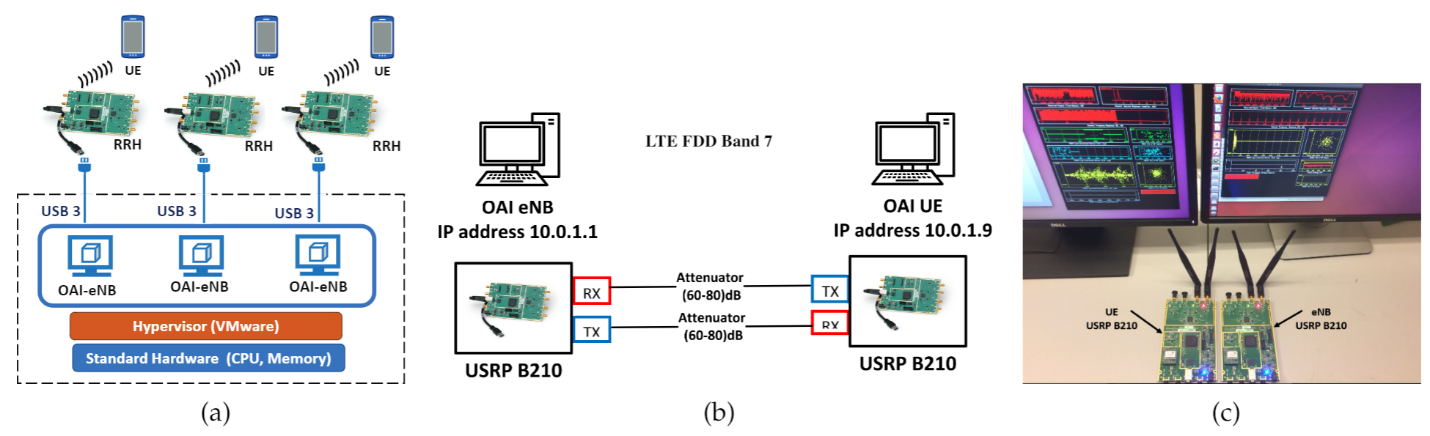
NG-RAN Testbed
In our recent works, we have implemented a small-scale C-RAN testbed to understand the computational requirement in the BBU pool, which provides us historical traces (via empirical models) for the design of the resource allocation algorithms based on cellular traffic, user mobility, and wireless channel condition. Fig. 2(a) shows the architecture of our testbed. The RRH front-ends of the C-RAN testbed are implemented using SDR USRP B210s, each supporting 2X2 MIMO with sample rate up to 62MS/s. In addition, each radio head is equipped with a GPSDO module for precise synchronization. Each instance of the virtual BBU is implemented using the OAI LTE stack, which is hosted in a VMware VM. All the RRHs are connected to the BBU pool via USB-3 connections. We set up the environment to emulate a ‘‘quiet’’ transmission between the evolved NodeB (eNB)and UE in which there is no interference from other devices (so as to have control of the environment). To accomplish this goal, we use two configurable attenuators (Trilithic Asia 35110D-SMA-R), which connect the Tx and Rx ports of the eNB to the Rx and Tx ports of the UE, respectively. Fig. 2(b) shows the configuration of the eNB-UE connection in the interference-free channel. As illustrated in Fig. 2(c), our C-RAN experimental testbed consists of one unit of UE and one unit of eNB, both implemented using the USRP B210 boards and running on OpenAirInterface (OAI). The OAI software instances of the eNB and UE run in separate Linux-based Intel x86-64 machines comprising of 4 cores for UE and 12 cores for eNB, respectively, with Intel i7 processor core at 3.6 GHz.
